
Introduction
Laissez-moi vous raconter l’histoire d’un jeune développeur web passionné. Après avoir terminé le développement de sa première fonctionnalité et l’avoir consciencieusement testé, il décide d’envoyer son code en production.
La fonctionnalité se porte bien et les utilisateurs sont heureux. Mais après quelques semaines, ce que tout développeur redoute le plus au monde, arrive.
Un crash en prod !
Un seul indice : “java.lang.OutOfMemoryError: Java heap space”.
Ce jeune développeur, c’était nous il y a un an. A travers notre retour d’expérience, on espère vous aider à analyser et traiter ce type d’incidents dangereux qui arrive plus souvent qu’on ne le croit.
Un memory leak, c’est quoi ?
Imaginons un parking, où chaque voiture entre et sort du parking. Les épaves sont toujours emmenées à la casse. Maintenant imaginons que le parking ne se vide jamais ou trop lentement et fini par être saturé. Nous avons un problème, les nouvelles voitures n’ont pas de place disponible.
Dans le cas de la JVM, chaque objet utilise une petite quantité de mémoire, mais est rapidement nettoyé par le garbage collector une fois qu’il n’est plus utilisé. Néanmoins, il arrive que des objets non utilisés continuent à exister indéfiniment.
Ces objets s’accumulent et finissent par empêcher les futures allocations nécessaires pour le bon fonctionnement de l’application.
Le danger des memory leaks est qu’ils passent souvent à travers les phases de tests et de quality assurance. En effet, ils arrivent souvent après une longue période de run de l’application, pouvant aller jusqu’à plusieurs semaines après la mise en production du code.
Dans notre cas, nous n’avions pas d’information sur l’état de la mémoire au moment du crash. Notre investigation a donc commencé par une mise en charge de l’application pour tenter de reproduire l’erreur.
Reproduction du memory leak détecté en production
L’objectif premier est de simuler l’usage de l’application qui a mené au crash. Savoir le reproduire nous permettrait de valider la résolution du memory leak.
Une première approche simpliste peut être de réaliser un script (en bash ou en python par exemple) afin d’envoyer les requêtes de manière automatisée.
Dans notre cas, il y avait nécessité de simuler de manière réaliste la montée en charge très courte et intense caractéristique du fonctionnement de notre application en contexte réel. Nous avons donc utilisé Gatling, un outil open source qui permet de réaliser des tests de charge efficaces et mesurables de manière simpliste. Il y a même maintenant un SDK java.
Pour observer l’impact de nos simulations, il faut être en mesure de visualiser les allocations mémoire au cours du temps. De nombreux outils peuvent le faire, voici ceux que nous avons utilisés :
- jstat ou jmap ( intégré au jdk )
En cas d’utilisation d’un JRE seul :
- En utilisant le standard JMX
- jattach
Si l’on préfère une visualisation sous forme de graphiques, on peut utiliser des outils de monitoring tels que VisualVM ou encore IntelliJ qui peuvent interpréter le standard JMX.
Si la mémoire utilisée augmente constamment, c’est le signe d’un memory leak. Il ne reste plus qu’à trouver la cause.
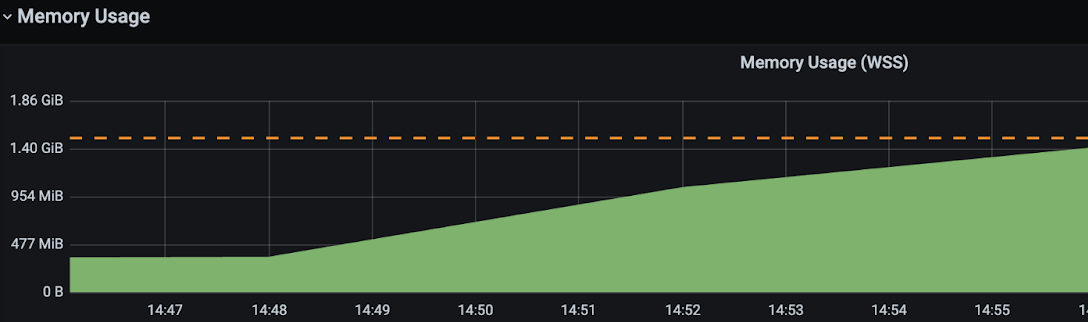
La figure ci-dessus représente l’utilisation de la heap d’une application qui contient un memory leak. On observe que l’on s’approche dangereusement de notre limite de mémoire.
Obtenir et analyser le heap dump
Afin de pouvoir analyser la mémoire utilisée, il était nécessaire de se connecter à la machine qui héberge notre application et d’utiliser des outils nous permettant d’extraire un heap dump.
Le heap dump est un fichier contenant l’ensemble des informations d’allocation mémoire de la JVM à un instant précis. Il se présente sous le format hprof.
Beaucoup d’outils existent pour obtenir ce heap dump, jmap étant le plus connu. Nous ne détaillerons pas ce fonctionnement dans cet article. Cet article vous donnera plus de détails sur le sujet.
Dans notre infrastructure, on utilise un JRE avec un système d’exploitation Alpine pour limiter la taille de nos images Docker. Nous étions également très limités sur la mémoire disque dans le container. Dû à ces contraintes, nous avons choisi Jattach qui est un outil standalone et ultra léger permettant d’extraire le heap dump de mémoire de la même manière que jmap.
Une fois le heap dump de mémoire obtenu, on peut l’analyser avec des outils comme VisualVM, Eclipse Mat ou encore avec le profiler de IntelliJ.
On commence par analyser la liste des objets présents au moment du heap dump.
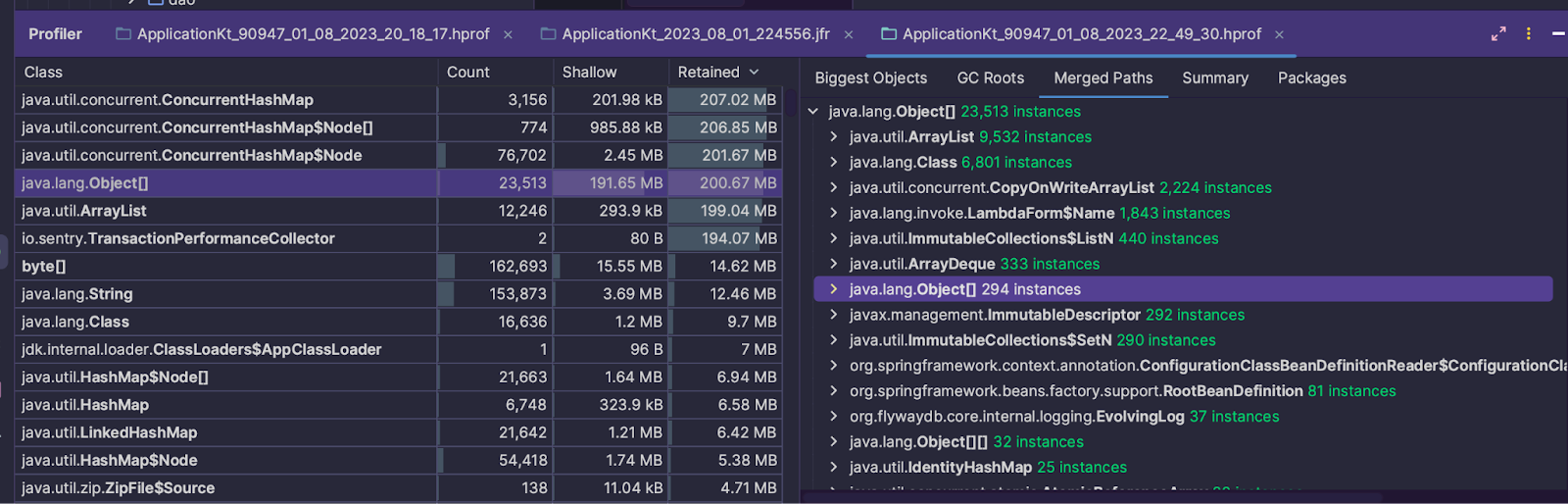
Dans le tableau ci-dessus,
- La colonne Count représente le nombre d’instance de la classe désignée.
- Shallow représente la place prise par ces objets.
- Retained est obtenue en sommant récursivement la mémoire des objets liés à l’objet d’origine (on parle alors d’Îlots mémoire). Cette colonne représente donc la quantité de mémoire qui serait libérée si les objets de la classe venait à être nettoyé par le garbage collector.
L’idée est de trouver quels objets se cachent derrière les plus gros objets gardés en mémoire. Très souvent les objets problématiques sont les collections de données puisqu’elles servent à contenir d’autres objets.
Ici, la classe ConcurrentHashMap est notre premier candidat.
Nous avons jusqu’ici analysé la mémoire à un instant T. Nous allons maintenant chercher à trouver les méthodes responsables de la production de ces objets en analysant le comportement de l’application en fonctionnement.
Pour cela, on va utiliser un flamegraph. Un flamegraph est un diagramme représentant chacune des méthodes associée à l’empreinte mémoire qu’elles ont générée au cours de la période d’analyse.
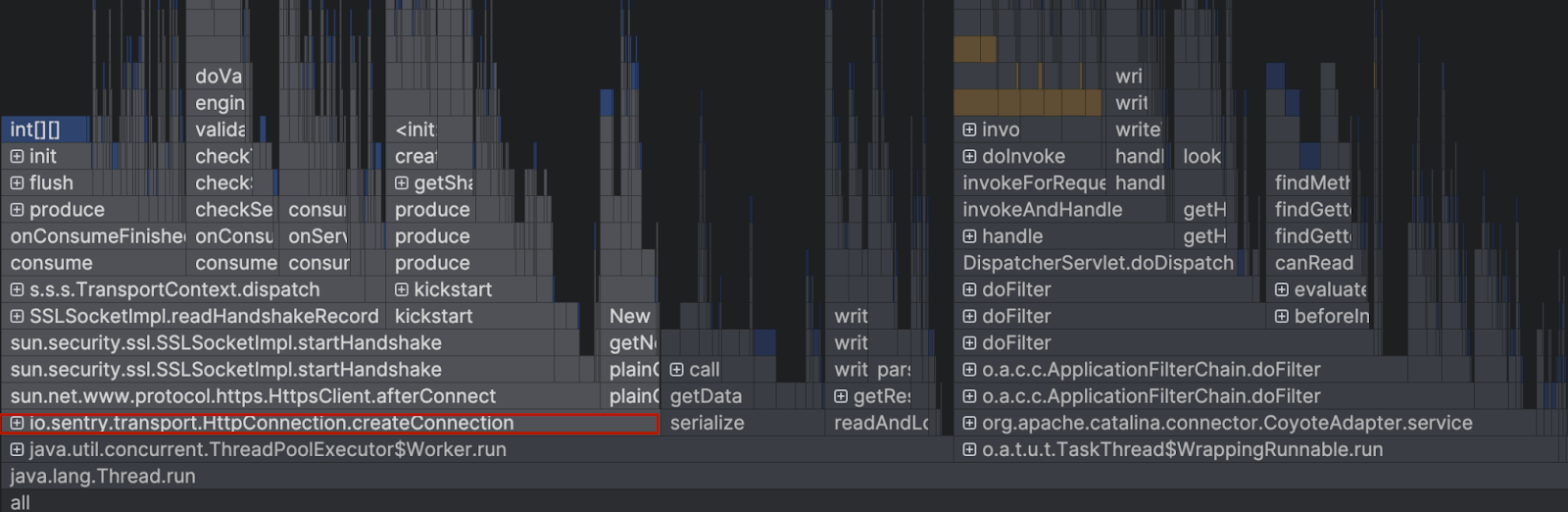
Chaque rectangle représente un appel de méthode. Sa largeur illustre la proportion de mémoire utilisée pendant la période d’analyse. Thread.run est le point d’entrée de notre application et on remarque que la méthode io.sentry.transport.HttpConnection.createConnection est la plus consommatrice en mémoire. On peut utiliser une vue en liste pour observer que cet appel est responsable de la moitié des allocations mémoires.
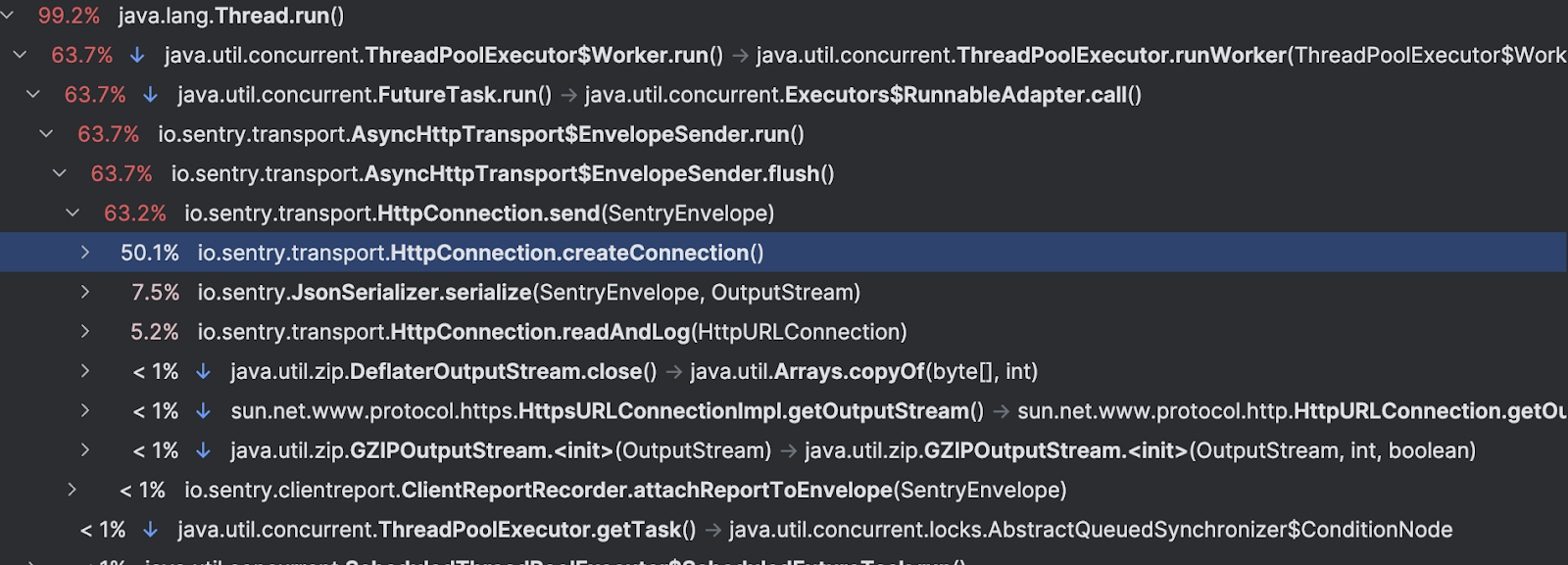
En remontant la chaîne d’appels, on s’aperçoit que chaque requête de notre application déclenche un envoie de données par Sentry via la Filterchain. Ces données sont stockées dans un concurrent Hashmap qui remplit la mémoire. Ces données sont envoyées à la plateforme Sentry via le client afin de faire des analyses de performances.
Nous avons donc trouvé notre présumé coupable. Nous allons chercher maintenant à résoudre le problème.
Pour confirmer notre hypothèse, nous avons désactivé la librairie. En rejouant nos tests de performances, nous nous sommes aperçu que nous n’avions plus le problème.
Avant de chercher plus loin, nous avons essayé de mettre à jour le SDK de Sentry et cela a suffit à mettre fin à la fuite mémoire.
Après quelques recherches dans les issues et les commits du SDK sentry-java, nous avons compris que la version que nous utilisions (6.12.1) avait bien un bug. Celui-ci a été corrigé dès la version 6.13 du SDK via cette merge request.
Victoire ! L’application a été remise sur pied et a pu de nouveau être utilisée en production avec succès. Ironiquement, c’est Sentry, la cause de notre crash, qui a pu nous avertir du problème.
Détecter un memory leak en production est une chose, néanmoins la meilleure approche est encore de les éviter en suivant un ensemble de bonnes pratiques préventives.
Mieux vaut prévenir que guérir
Voici une liste non exhaustive de conseils pour éviter les memory leaks.
Il est important de connaître les limites de son application. Pour ce faire, il est intéressant d’utiliser des tests de charge pour vérifier que son application fonctionne correctement tant en charge nominale mais aussi et surtout dans des scénarios extrêmes mais réalistes (on peut penser par exemple aux périodes de fête pour Amazon).
Monter les versions des libs, rester à jour est toujours une bonne pratique tant en terme de sécurité que pour la prévention de bug. Ça aurait pu nous éviter le problème dans notre situation. Des outils comme dependabot existent pour mettre à jour automatiquement nos dépendances.
Les outils d’analyse statique tels que Sonar permettent parfois de détecter des codes smells susceptibles de produire des fuites mémoires.
Aussi, un bon suivi des logs et des metrics donne plus de visibilité. Ajouter de l’alerting permet d’être plus réactif. Nous recommandons l’utilisation de Datadog ou d’une stack ELK pour une solution open source.
Enfin, malgré toutes les précautions prises, des problèmes peuvent quand même arriver en production. Il est alors important d’être en mesure de collecter un maximum d’informations au moment du crash de l’application. L’usage de l’option HeapDumpOnOutOfMemoryError sur le JVM, permet d’obtenir le précieux fichier de mémoire qui vous permettra de gagner beaucoup de temps d’analyse.
Conclusion
La détection et la résolution des memory leaks peuvent s’avérer complexes, mais une approche méthodique et des outils appropriés peuvent grandement faciliter le processus.
Pour rappel, vous devez essayer de :
- Collecter un maximum d’informations à travers les logs, un heap dump si disponible
- Analyser des heap dumps de mémoire
- Essayer de reproduire la fuite mémoire
- Fixer le problème rencontré
- Valider la correction sur vos environnements de recette
On espère qu’à travers cet article vous arriverez à vous lancer dans l’étude et le traitement de ces erreurs qui font peur.
Par Iliès Beldjilali & Lansana Diomande